
L’IA GÉNÉRATIVE : UNE PETITE RÉVOLUTION DANS LA CRÉATION ET L’ANNOTATION DES JEUX DE DONNÉES D’IMAGES
L’intelligence artificielle transforme l’efficacité et la productivité des entreprises, grâce à sa capacité d’automatiser des tâches complexes et d’analyser de vastes volumes de données. L’adage “le chemin vers l’IA est pavé de données” souligne l’importance de la collecte et de l’analyse de données pour construire des systèmes d’IA performants. L’adoption de l’IA s’accélère, touchant autant le grand public que les ingénieurs, qui exploitent son potentiel pour révolutionner divers domaines.
Par LOÏCK BRIOT (N13), responsable IA et Logiciel au TechLab Mines Nancy – loick.briot@mines-nancy.org
Les ingénieurs exploitent l’IA de multiples façons pour bouleverser les pratiques traditionnelles : de l’analyse et la classification avancée des données, qui permettent d’extraire des insights précieux, à la génération automatique de code, qui promet de simplifier le développement logiciel. L’IA joue également un rôle crucial dans l’optimisation des processus industriels, rendant les chaînes de production plus efficaces, et dans l’automatisation des tâches administratives répétitives, libérant ainsi du temps pour des activités à plus forte valeur ajoutée. Sa capacité à détecter et prévenir la fraude est inestimable dans le secteur financier, tandis que la personnalisation de l’expérience client qu’elle permet redéfinit les standards d’excellence dans le domaine du commerce.
DATA AUGMENTATION
Jusqu’à récemment, les outils d’IA générative d’images n’étaient pas associés à l’arsenal technologique de l’ingénieur. Cependant, leur potentiel pour transformer les industries commence à être reconnu, notamment dans l’analyse et la compréhension d’images. L’enrichissement des données (data augmentation) est une technique qui augmente artificiellement le volume de données à disposition pour l’entraînement des modèles de Deep Learning. Traditionnellement, cette technique reposait sur des ajustements mineurs apportés aux données existantes, tels que des rotations, des déplacements, des ajustements de l’échelle, des modifications de la luminosité ou l’ajout de flou, pour générer de nouvelles images qui contribuent à diversifier l’ensemble de données d’origine.
Ces méthodes conventionnelles ont certes joué un rôle important dans l’amélioration de la robustesse des modèles de Deep Learning. Cependant, les possibilités offertes par les derniers outils modernes dédiés à l’expansion des ensembles de données représentent un saut qualitatif. Ces outils sont capables de générer de nouveaux points de données extrêmement variés à partir des données existantes, allant bien au-delà de simples transformations géométriques ou de modifications de l’apparence. En créant des images entièrement nouvelles qui conservent la cohérence et la pertinence par rapport à l’ensemble original de données, ils permettent un enrichissement des données plus dense et plus profond.

Les outils de création d’images tels que Dall-E, Midjourney et Stable Diffusion représentent une avancée majeure dans ce domaine. Cette approche novatrice non seulement facilite la préparation des ensembles de données nécessaires à l’entraînement des modèles d’IA spécialisés, mais encourage également une synergie où des IA génèrent les données d’entraînement pour d’autres IA, optimisant ainsi l’efficacité du processus d’apprentissage. Cette interaction promet d’ouvrir des horizons nouveaux dans l’application de l’IA en ingénierie, rendant la formation des modèles d’IA plus rapide, plus flexible et plus accessible en coût comme en temps.
INNOVATION DANS L’ANNOTATION DES JEUX DE DONNÉES
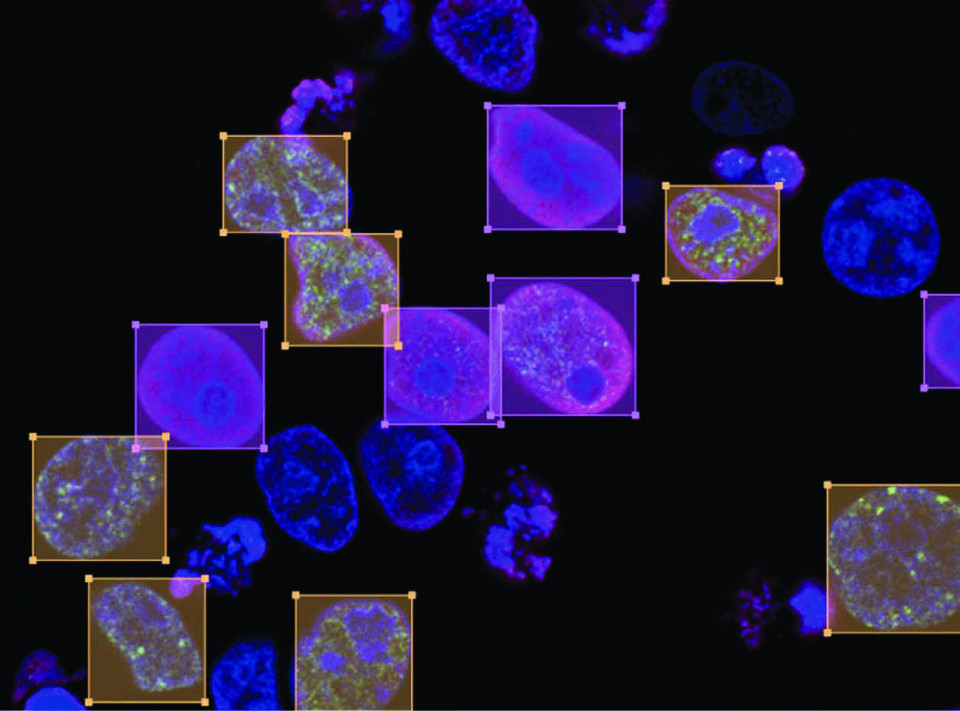
L’émergence de modèles génériques de reconnaissance d’objets dans des images promet également de révolutionner le développement de l’intelligence artificielle, particulièrement dans le domaine exigeant de l’annotation des jeux de données constitués d’images.
De gros modèles génériques (qui demandent une grosse puissance de calculs) sont maintenant disponibles sur le marché, et savent reconnaître un peu tout et n’importe quoi (on peut par exemple écrire comme prompt “retrouver l’animal dans l'image”), ce qui permet de labelliser tout seul des données, données qui seront utilisées pour entrainer des plus petits modèles spécifiques (ils ne savent reconnaitre que l’animal en question, rien d'autre), mais ces petits modèles bien moins gourmands peuvent tourner sur des petits ordinateurs.
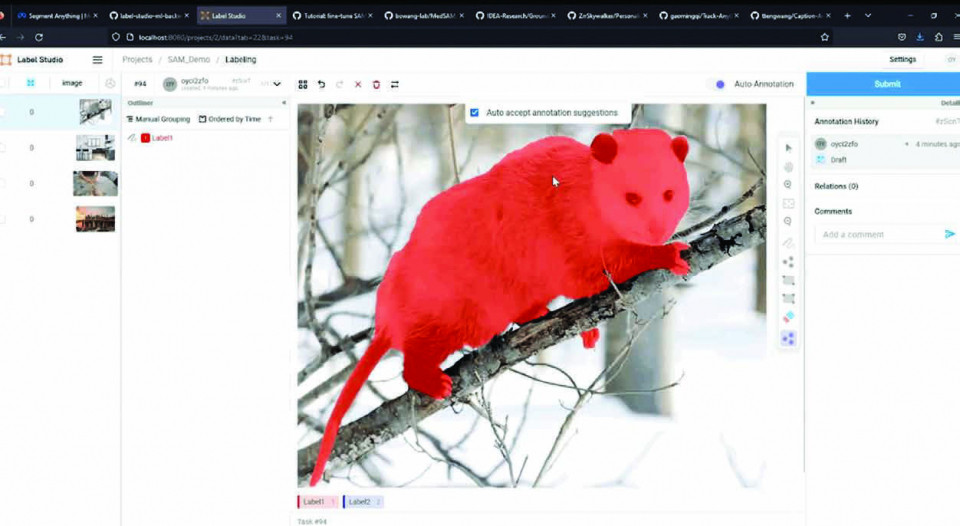
Des outils de pointe tels que ChatGPT Vision d’OpenAI, le SAM de Meta, ainsi que des projets open source, comme Grounding Dino ou LLava, sont en première ligne de cette avancée, optimisant l’efficacité, la précision et la rapidité de l’annotation tout en réduisant la charge de travail humaine.
travail humaine. Bien que les modèles tels que ChatGPT Vision ou Grounding Dino exigent une puissance de calcul importante et consomment beaucoup d’énergie, ils sont relativement lents, avec seulement 2 à 3 inférences par seconde. Ils ne sont donc pas idéaux pour une utilisation en temps réel, mais ils peuvent être extrêmement utiles lors de la phase préparatoire d’annotation, actuellement gérée par des opérateurs humains. L’objectif est de gagner du temps dans cette étape préparatoire pour ensuite entraîner des modèles spécifiques plus petits, plus performants, et économiquement plus viables. À titre d’exemple, des modèles comme YOLOv8 nano peuvent atteindre jusqu’à 80 inférences par seconde, bien au-delà des 30 images par seconde d’un flux vidéo standard, ce qui les rend particulièrement adaptés à une utilisation en temps réel. Cette innovation est avantageuse pour l’entraînement de modèles spécialisés dans la détection d’objets et la segmentation sémantique, où une grande quantité de données annotées est essentielle. Les modèles de détection d’objets nécessitent de nombreuses annotations pour repérer et localiser précisément les objets, tandis que la segmentation sémantique, qui attribue chaque pixel à une catégorie spécifique, requiert des annotations de haute précision pour que les modèles puissent interpréter finement les scènes visuelles.
Toutefois, malgré les avancées qu’apporte l’automatisation de l’annotation des données dans le développement de l’intelligence artificielle, il est crucial de reconnaître que cette approche peut introduire des biais dans les données générées et annotées. Ces biais peuvent provenir de plusieurs sources, notamment des préjugés inhérents aux données d’entraînement utilisées pour former les modèles d’annotation automatique eux-mêmes, ce qui peut conduire à des annotations inexactes ou trompeuses.
IA ET HUMAIN, ENSEMBLE
La supervision humaine est cruciale pour garantir l’efficacité et la fiabilité des technologies d’annotation automatique dans le développement de l’IA. Cette étape assure un équilibre vital entre les avantages de l’automatisation, comme la réduction du temps d’annotation, et la nécessité de maintenir des données justes et fiables. En adoptant une méthode rigoureuse incluant des révisions régulières par des humains, il est possible de diminuer le risque de biais et d’enrichir la qualité des annotations.
De plus, la génération automatique d’images apporte son lot de questionnement en matière de droits d’auteur. Lorsque des outils d’IA comme Dall-E, Midjourney, et Stable Diffusion créent des images à partir de descriptions textuelles, ils peuvent s’appuyer sur des bases de données contenant possiblement des œuvres protégées par des droits d’auteur, posant ainsi des défis en termes de propriété intellectuelle. La régulation de ces technologies devient cruciale pour respecter la législation sur les droits d’auteur et assurer une utilisation éthique. Elle vise à protéger les créateurs et à assurer que l’innovation dans le domaine de la génération d’images par IA se déroule dans un cadre légal, respectant à la fois le progrès technologique et les droits des individus. Il est remarquable que cette problématique s’applique, quasiment à l’identique, à la rédaction par outils d’IA des demandes de brevets de produits ou de process, voire à la brevetabilité d’inventions auxquelles un algorithme d’IA a contribué.
Ainsi, bien que l’automatisation de l’annotation des données présente des défis, notamment en termes de gestion des biais, les avantages en termes de gain de temps et d’efficacité sont indéniables. Avec une surveillance humaine attentive et un cadre d’utilisation bien défini, les outils d’annotation automatique peuvent jouer un rôle crucial dans l’accélération du progrès de l’intelligence artificielle, tout en garantissant le droit d’auteur et la création de modèles justes et précis. Dans cette démarche, l’Union européenne est devenue le premier continent à proposer un cadre réglementaire spécifique à la révolution de l’IA (“AI Act” finalisé en décembre 2023) pour essayer de garantir un progrès éthique. ▲
 |  |
L’auteur remercie Allan Oliver, en stage au TechLab Mines Nancy dans le cadre d’une L3 information-communication, pour son aide dans la rédaction de cet article.
 | LOÏCK BRIOT (N13), Spécialisé dans la conception d’Assistants Virtuels, Loïck a été CTO d’une start-up (2016-2021) à Luxembourg. Depuis septembre 2021, il est responsable Intelligence Artificielle et Logiciel au TechLab Mines Nancy, où il encadre des projets étudiants en lien avec l’Industrie (IA, robotique, 5G…). |

Commentaires0
Veuillez vous connecter pour lire ou ajouter un commentaire
Articles suggérés

